Data locality describes the process of moving computation close to data in order to avoid network traffic and improve overall throughput.
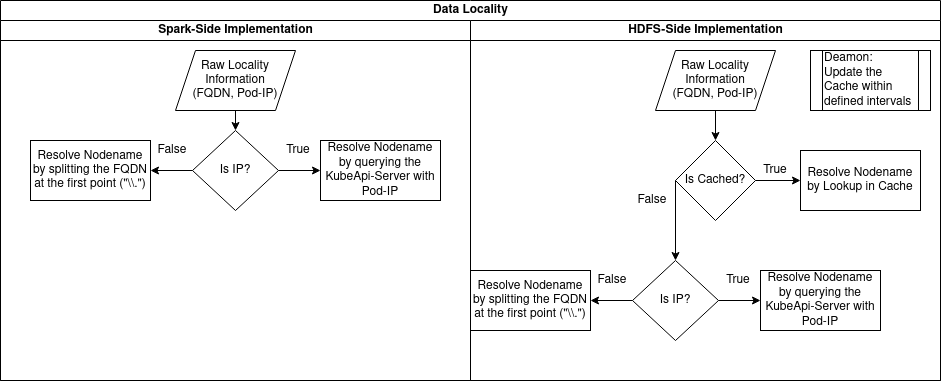
The Hadoop ecosystem as well as Apache Spark are emphasizing the importance of data locality for performant computation and are therefore implementing data locality where possible. The Hadoop Distributed File System (HDFS) provides a strong interface, enabling application to gather locality information about the data they requested. Projects like Apache Spark, which are designed to natively operate with HDFS, are then able to use this information to leverage their computational performance.
Unfortunately, when running containerized instances of HDFS and Spark on the cluster orchestrator Kubernetes, their default data locality implementations are broken.
This blog post describes the data locality implementations of Apache Spark and HDFS, why it is broken when running on Kubernetes and how we resolved it.
Spark HDFS data locality
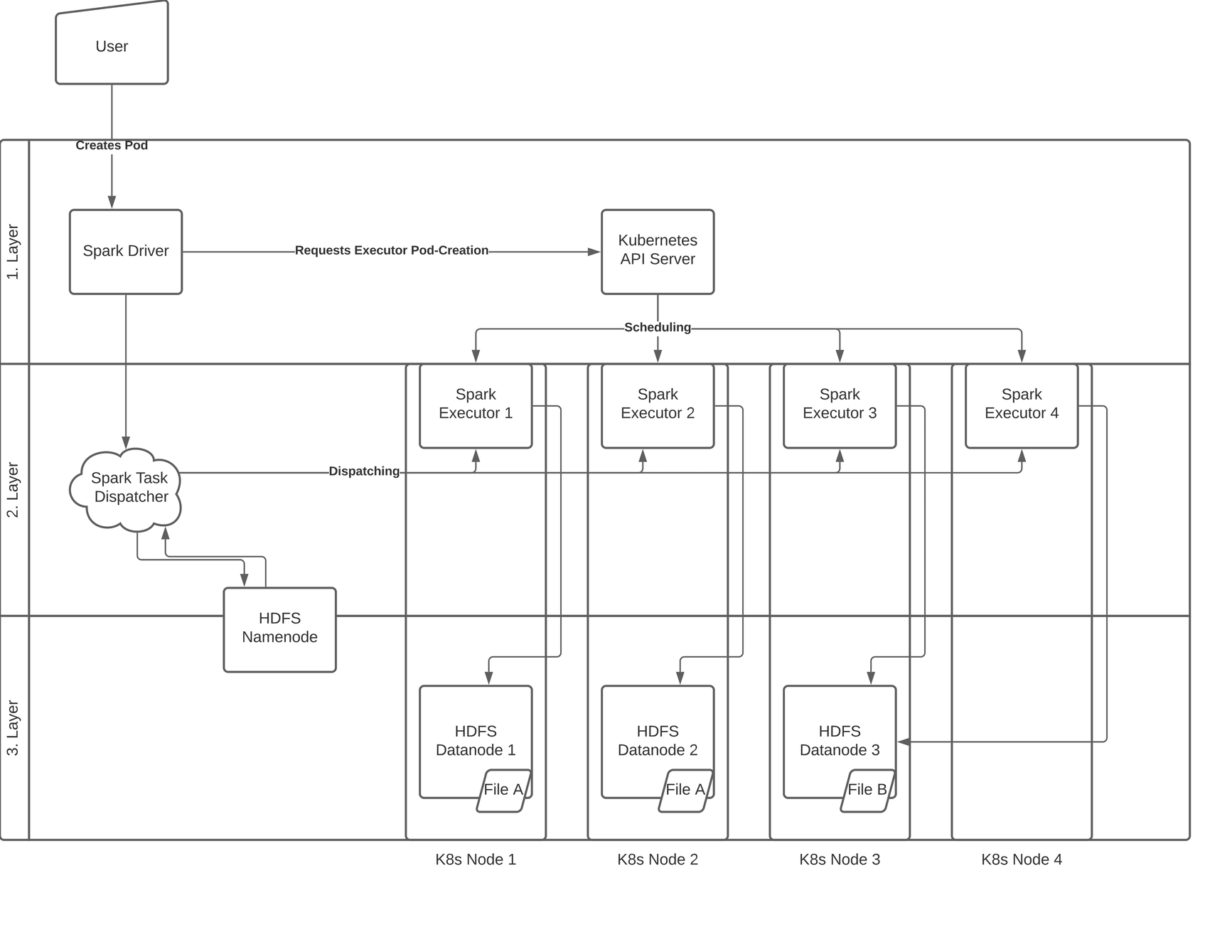
When running Spark alongside HDFS, data locality generally consists of 3 layers/stages.
Every layer is responsible for another aspect of data locality.
The aim of the first layer is to ensure, that spark executor are created on HDFS-datanode-hosting hosts.
This is rather an obvious but essential prerequisite.
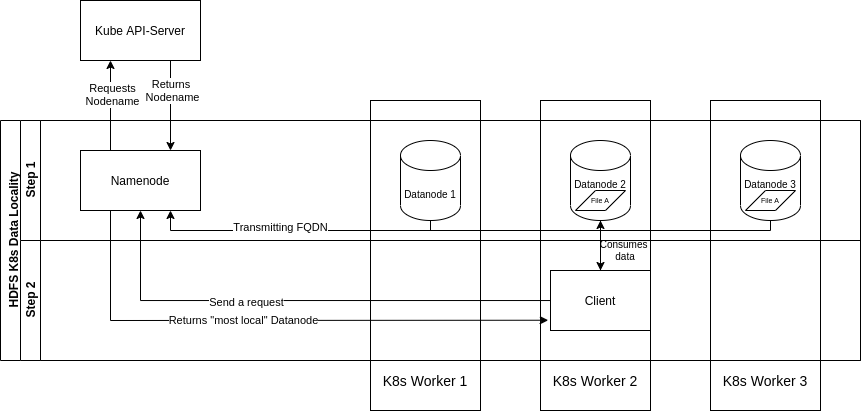
The second stage ensures, that spark tasks requiring specific data from HDFS are dispatched to executors, which are
located on the same hosts as the datanode holding this data.
Once all tasks have been scheduled correctly, the third stage has to secure that the executors are effectively using the data from their „most local“ datanode.
The problem when running on Kubernetes
At TIKI, our infrastructure relies on Kubernetes container orchestration.
When speaking about data locality on Kubernetes, we mean node-locality referring to Kubernetes worker nodes.